Tutorial 12: Loan amount prediction using DAI agents
Overview
Enterprise h2oGPTe agents allow you to create machine learning experiments using natural language, eliminating the need to write code or manually configure experiment parameters.
This tutorial demonstrates how to use Enterprise h2oGPTe agents with H2O Driverless AI (DAI) to build a regression model for predicting loan amounts in the banking and financial services industry.
In this use case, you need to predict loan amounts using historical loan application data. Build a regression model that predicts the loan amount while prioritizing interpretability to ensure actionable insights for your business teams.
Industry: Banking and Financial Services
Business objective: Optimize loan approval strategies by predicting appropriate loan amounts based on applicant characteristics, income, and credit history.
Technical requirements:
- Task: Regression
- Target column:
LoanAmount - Dataset: Loan prediction dataset
- Evaluation metric: RMSE (Root Mean Squared Error)
- Priority: High interpretability (10) for regulatory compliance and business transparency
- Secondary priorities: Balanced accuracy (1) and time (1) for rapid deployment
Objectives
- Build a DAI regression model: Create a Driverless AI experiment using Enterprise h2oGPTe agents through natural language prompts
- Configure experiment settings: Specify interpretability, accuracy, time, and scorer parameters for your use case
- Analyze model results: Explore variable importance, model diagnostics, and interpretation reports
- Deploy models: Download MOJO scoring pipelines for production deployment
Prerequisites
- Enterprise h2oGPTe instance with agent functionality enabled
- (Optional) Review the Traditional Enterprise h2oGPTe workflow
Step 1: Enable Data Science Agent
Before creating your experiment, you need to enable the Data Science Agent in your chat. The Data Science Agent is a specialized agent type designed for data analysis, statistics, and analytics workflows with direct integration to H2O Driverless AI.
- Navigate to the Chats tab and click + New chat.
- Click Agent to enable agent functionality.
- In the agent type dropdown menu, select Data Science Agent.
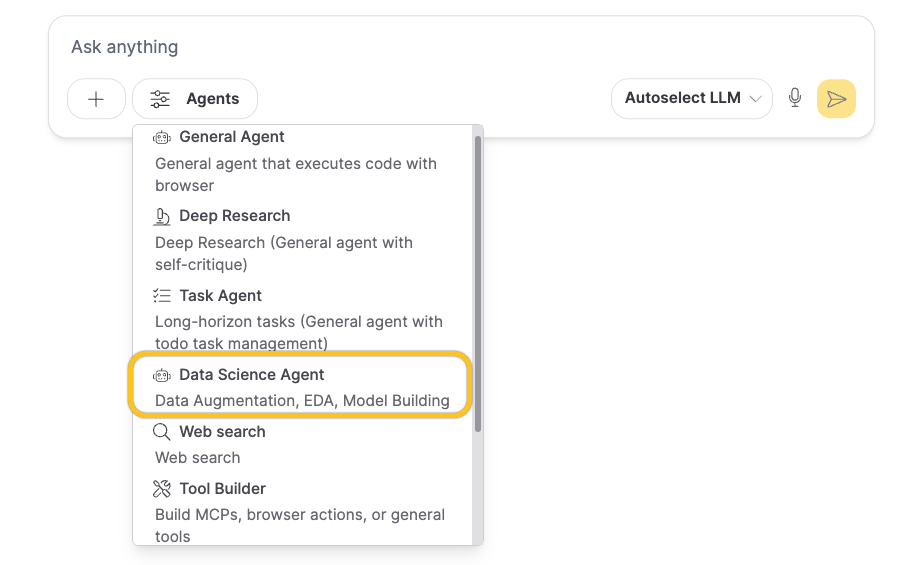
Enterprise h2oGPTe offers two agent types:
- General Agents: For tasks like research, content creation, and automation tasks
- Data Science Agent: For specialized tasks like data analysis and machine learning with H2O Driverless AI
DAI experiments may require multiple agent turns to complete. If your experiment stops prematurely with a message about reaching the turn limit, increase the agent turns setting in your chat configuration.
The default max turns vary by agent accuracy level:
- Quick: 5 turns
- Basic: 10 turns
- Standard: 20 turns
- Maximum: 80 turns
For DAI experiments involving data loading, experiment creation, monitoring, and results analysis, consider using the Basic or Standard accuracy setting. See Max Agent Turns for details.
Step 2: Review the dataset and experiment configuration
Review the dataset
The loan prediction dataset contains historical loan application data with the following characteristics:
- Dataset: mock_loan_prediction_train_data.csv
- Size: 614 loan applications
- Features: 13 columns including:
- Applicant demographics: Gender, Married, Dependents, Education, Self_Employed
- Financial information: ApplicantIncome, CoapplicantIncome, LoanAmount (target), Loan_Amount_Term
- Credit factors: Credit_History, Property_Area, Loan_Status
Configure the experiment
For this banking use case, prioritize interpretability to ensure regulatory compliance and stakeholder understanding:
| Parameter | Value | Rationale |
|---|---|---|
| Interpretability | 10 | Maximum explainability for your credit officers and regulatory compliance |
| Accuracy | 1 | Balanced approach prioritizing model simplicity over marginal accuracy gains |
| Time | 1 | Rapid model development for quick deployment |
| Scorer | RMSE | Standard regression metric measuring prediction error in dollars |
Understanding DAI experiment settings:
-
Accuracy (1-10): Controls model complexity and feature engineering sophistication. Higher values enable more extensive feature evolution and model tuning, leading to better performance but longer experiment times and less interpretable models.
-
Time (1-10): Specifies experiment duration and iteration count. Higher values allow more model exploration and ensemble building. DAI automatically activates early stopping for Time > 1.
-
Interpretability (1-10): Controls model transparency and explainability. Higher values restrict complex features and favor simpler models (e.g., linear models, monotonic constraints). Lower values enable advanced feature engineering that improves accuracy at the cost of explainability.
-
Scorer: Evaluation metric for model selection. Common regression scorers include:
- RMSE: Root Mean Squared Error (penalizes large errors)
- MAE: Mean Absolute Error (treats all errors equally)
- R²: Coefficient of determination (explains variance)
Step 3: Create the loan amount prediction experiment
Create the regression experiment using a natural language prompt. The agent will automatically configure and launch the DAI experiment based on your requirements.
-
In the Ask anything box, use the following template for your use case:
Create a DAI machine learning model for [PROBLEMTYPE]. Use this dataset:
[YOUR DATASET URL]
The target column is "[YOUR TARGET COLUMN]". Prioritize interpretability with a setting of [INTERPRETABILITY LEVEL]. Use [EVALUATION METRIC] as the scorer. Set accuracy and time to [ACCURACY SETTING] for quick deployment.
Name the experiment "[EXPERIMENT NAME]". -
For this loan amount prediction use case, here's an example prompt you can use directly:
Create a DAI machine learning model for regression. Use this dataset:
https://h2o-usecase-catalog.cdn.h2oai.com/usecase-demo-files/mock_loan_prediction_train_data.csv
The target column is "LoanAmount". Prioritize interpretability with a setting of 10. Use RMSE as the scorer. Set accuracy and time to 1 for quick deployment.
Name the experiment "Loan_Amount_Prediction_Banking". -
(Advanced prompt - optional) Explicitly specify which features to include or exclude:
Create a DAI regression experiment to predict LoanAmount using this dataset:
https://h2o-usecase-catalog.cdn.h2oai.com/usecase-demo-files/mock_loan_prediction_train_data.csv
Include only these features: ApplicantIncome, CoapplicantIncome, Credit_History,
and Loan_Amount_Term. Exclude all demographic features (Gender, Married, Dependents,
Education, Self_Employed, Property_Area).
Use interpretability: 10, accuracy: 1, time: 1, scorer: RMSE.
Name the experiment "Loan_Amount_Financial_Features_Only".
Use only Driverless AI. Do not build custom Python models or compare with other
modeling approaches.Keeping agents focusedTo keep the agent from building custom models or going beyond your request, explicitly instruct it to "use only Driverless AI" and "do not build custom Python models." This helps the agent stay focused on DAI workflows rather than implementing alternative approaches.
-
Click
Submit. -
(Optional) While the agent processes your request, monitor progress in real-time by toggling the Show Thoughts option:
Step 4: Analyze experiment results
After the experiment completes, the agent provides analysis including dataset statistics, model performance metrics, feature importance, exploratory data insights, and business recommendations.
The agent also provides a link to the experiment in Driverless AI for further exploration.
Review DAI experiment results
The output from h2oGPTe contains the following information regarding the DAI experiment:
Dataset: 614 loan applications with 13 features. Notable missing values: Credit_History (8.14%), Self_Employed (5.21%), LoanAmount (3.58%).
Model performance:
| Metric | Validation Score | Test Score |
|---|---|---|
| RMSE | 61.69 ± 7.88 | 47.18 |
| R² Score | - | 0.999 |
| MAPE | - | 1.29% |
The model achieves accurate predictions with mean absolute error of 1.64 and 100% prediction interval coverage.
Top features:
- ApplicantIncome (0.57 correlation with LoanAmount)
- CoapplicantIncome
- Credit_History
- Loan_Amount_Term
- Education
Key insights:
- Education impact: Graduates receive higher loan amounts (154.06 vs 118.41 for non-graduates)
- Employment status: Self-employed applicants receive ~21% higher loans (172.00 vs 141.75)
- Loan-to-income ratio: Average 2.38% of total income (range: 1.93%-2.81%)
- Property area: Rural areas slightly higher (152.26) vs Urban (142.20)
Business recommendations:
- Implement automated loan amount recommendations
- Develop targeted products
- Education-based marketing
- Use prediction intervals
- Improve data collection
- Customer-facing calculator
- Income-based loan guidelines
Request additional analysis from the Data Science Agent in h2oGPTe
Request additional analysis using natural language:
Variable importance analysis:
Show me variable importance for both original and engineered features
Model diagnostics:
Create a model diagnostic report with actual vs predicted plots and residual analysis
Interpretability report:
Generate an MLI (Machine Learning Interpretability) report with Shapley values and feature contributions
Prediction analysis:
Show me predictions on the test set with confidence intervals
Download artifacts:
Download the MOJO scoring pipeline for production deployment
Download experiment documentation:
Generate an AutoDoc report for my loan prediction experiment including all visualizations, model explanations, and performance metrics
Available DAI analysis options:
| Analysis type | Description | Use case |
|---|---|---|
| Variable Importance | Shows impact of original and engineered features | Understand which features drive predictions |
| Model Diagnostics | Scoring with visualization plots | Evaluate model performance across metrics |
| MLI Report | Disparate Impact Analysis, Sensitivity Analysis, Shapley values, surrogate decision trees | Ensure fairness, understand feature contributions, explain individual predictions |
| Predictions | Training/test predictions with confidence intervals | Validate model on new data |
| MOJO Pipeline | Production-ready scoring pipeline | Deploy model to production systems |
| AutoDoc | Automated documentation of the experiment | Share results |
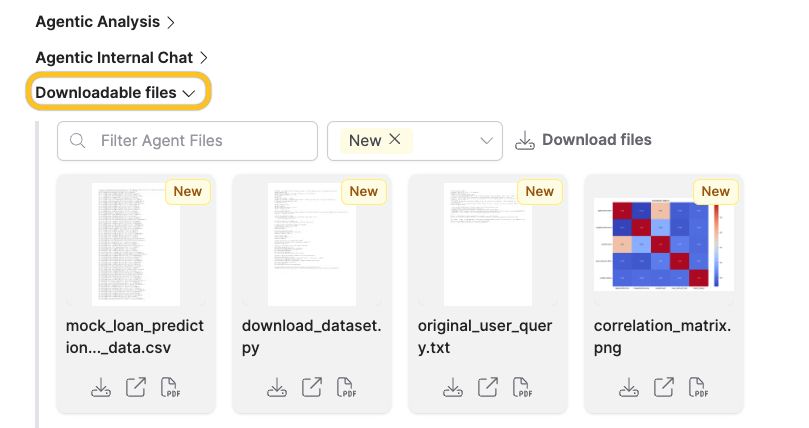
To download files generated by the agent for this experiment, click the Download files dropdown displayed at the end of the experiment:
Step 5: Deploy and use the model
Once you've validated the model, deploy it to production:
Download MOJO scoring pipeline
Request the MOJO scoring pipeline for production deployment:
Download the MOJO scoring pipeline for my Loan Amount Prediction experiment
The agent downloads and extracts the MOJO (Model Object, Optimized) package. This artifact includes everything you need to deploy your model:
What you receive:
- Core files:
pipeline.mojo: Main scoring pipelinemojo2-runtime.jar: Java runtime for scoring
- Examples and documentation:
- Sample input data (
example.csv) - Python example (
example.py) - Shell scripts (
run_example.sh) - Model visualizations and README
- Sample input data (
Deployment options:
The agent provides instructions for multiple deployment environments:
- Java runtime: Includes command-line examples and memory allocation recommendations
- Python integration: Provides code samples using
datatableanddaimojopackages - C++ runtime: Offers alternative deployment path
- License configuration: Documents environment variables, JVM properties, and classpath setup
Additional capabilities:
- Shapley values: Generate explanations for individual predictions
- Prediction intervals: Obtain confidence intervals for regression predictions
- Feature contributions: Analyze original feature impact on predictions
The agent also provides links to H2O.ai's deployment templates on GitHub for production integration scenarios.
Compare models for deployment:
Use the prompt below to compare different machine learning models from your experiment and identify the best one for deployment:
Compare the Linear Regression and GLM models from my loan prediction experiment and recommend which one to deploy based on interpretability and RMSE performance
Summary
In this tutorial, you learned how to:
- Select the Data Science Agent type - a specialized agent optimized for data analysis and machine learning
- Enable and configure the Data Science Agent for DAI integration
- Create a regression experiment using natural language prompts
- Specify experiment parameters (interpretability, accuracy, time, scorer) for banking use cases using prompts
- Analyze results including variable importance, model diagnostics, and interpretability reports
- Deploy models using MOJO scoring pipelines
This workflow demonstrates how Enterprise h2oGPTe's Data Science Agent enables you to build machine learning models without writing code, leveraging the power of H2O Driverless AI through natural language interaction.
Next steps
After completing this tutorial, you can:
- Explore other DAI experiment types: Agent tool calling and Driverless AI integration
- Learn about custom agent tools: Tutorial 9: Creating and using a custom agent tool
- Understand agent reasoning: Tutorial 10: Visualize your agent's actions with Mermaid charts
- Review agent tool configuration: Agent tool configuration
- Submit and view feedback for this page
- Send feedback about Enterprise h2oGPTe to cloud-feedback@h2o.ai